MySQL的Join算法
MySQL的Join算法
Index Nested-Loop Join
1 | |

图1 使用索引字段join的 explain结果
可以看到,在这条语句里,被驱动表t2的字段a上有索引,join过程用上了这个索引,因此这个语句的执行流程是这样的:
- 从表t1中读入一行数据 R;
- 从数据行R中,取出a字段到表t2里去查找;
- 取出表t2中满足条件的行,跟R组成一行,作为结果集的一部分;
- 重复执行步骤1到3,直到表t1的末尾循环结束。

在这个join语句执行过程中,驱动表是走全表扫描,而被驱动表是走树搜索。
假设被驱动表的行数是M。每次在被驱动表查一行数据,要先搜索索引a,再搜索主键索引。每次搜索一棵树近似复杂度是以2为底的M的对数,记为log2M,所以在被驱动表上查一行的时间复杂度是 2*log2M。
假设驱动表的行数是N,执行过程就要扫描驱动表N行,然后对于每一行,到被驱动表上匹配一次。
因此整个执行过程,近似复杂度是 N + N2log2M。
显然,N对扫描行数的影响更大,因此应该让小表来做驱动表。
如果被驱动表的连接字段t2.a没有索引,则被驱动表也会全表扫描,整个过程的复杂度则为MN,这种算法叫做“Simple Nested-Loop Join”。==然而MySQL并没有使用这种算法,而是使用了另一个叫作“Block Nested-Loop Join”的算法,简称BNL。==*
Block Nested-Loop Join
不要出现这种算法
这时候,被驱动表上没有可用的索引,算法的流程是这样的:
- 把表t1的数据读入线程内存join_buffer中(如果放不下表t1的所有数据话,策略很简单,就是分段放。),由于我们这个语句中写的是select *,因此是把整个表t1放入了内存;
- 扫描表t2,把表t2中的每一行取出来,跟join_buffer中的数据做对比,满足join条件的,作为结果集的一部分返回。
这个过程的流程图如下:
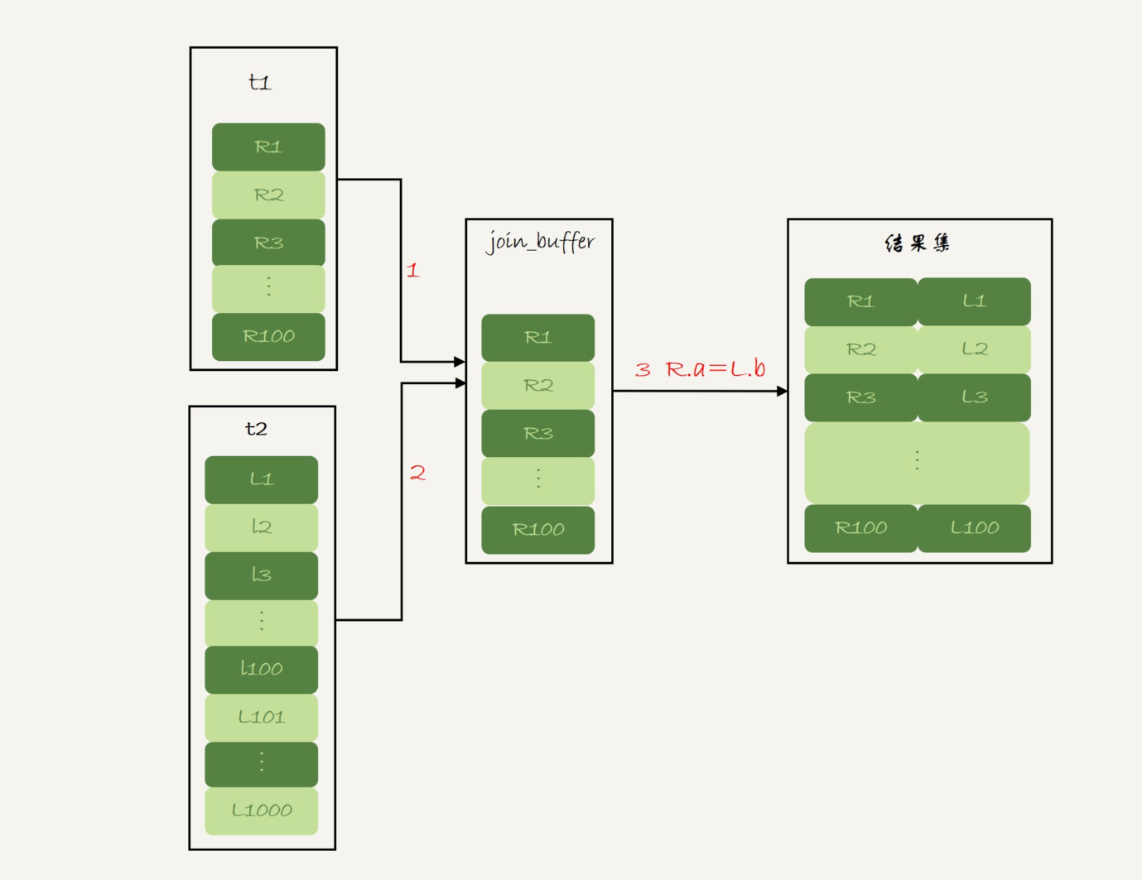
图3 Block Nested-Loop Join 算法的执行流程
对应地,这条SQL语句的explain结果如下所示:

图4 不使用索引字段join的 explain结果
可以看到,在这个过程中,对表t1和t2都做了一次全表扫描,因此总的扫描行数是1100。由于join_buffer是以无序数组的方式组织的,因此对表t2中的每一行,都要做100次判断,总共需要在内存中做的判断次数是:1001000=10万次。(By default, MySQL (8.0.18 and later) employs hash joins whenever possible.已经支持hash join了;在该案例中扫描的应该是1000次)*
前面我们说过,==如果使用Simple Nested-Loop Join算法进行查询,扫描行数也是10万行。因此,从时间复杂度上来说,这两个算法是一样的。但是,Block Nested-Loop Join算法的这10万次判断是内存操作,速度上会快很多,性能也更好。==
总结:
- 如果可以使用Index Nested-Loop Join算法,也就是说可以用上被驱动表上的索引,其实是可以使用Join的。
- 应该用小表驱动大表,**小表指的是两个表按照各自的条件过滤,过滤完成之后,计算参与join的各个字段的总数据量,数据量小的那个表,就是“小表”**
Multi-Range Read
MRR原理是利用了顺序读,
借助MRR优化的设计思路。此时,语句的执行流程变成了这样:
- 根据索引a,定位到满足条件的记录,将id值放入read_rnd_buffer中;
- 将read_rnd_buffer中的id进行递增排序;
- 排序后的id数组,依次到主键id索引中查记录,并作为结果返回。
这里,read_rnd_buffer的大小是由read_rnd_buffer_size参数控制的。如果步骤1中,read_rnd_buffer放满了,就会先执行完步骤2和3,然后清空read_rnd_buffer。之后继续找索引a的下个记录,并继续循环。
另外需要说明的是,如果你想要稳定地使用MRR优化的话,需要设置set optimizer_switch="mrr_cost_based=off"。(官方文档的说法,是现在的优化器策略,判断消耗的时候,会更倾向于不使用MRR,把mrr_cost_based设置为off,就是固定使用MRR了。)
下面两幅图就是使用了MRR优化后的执行流程和explain结果。
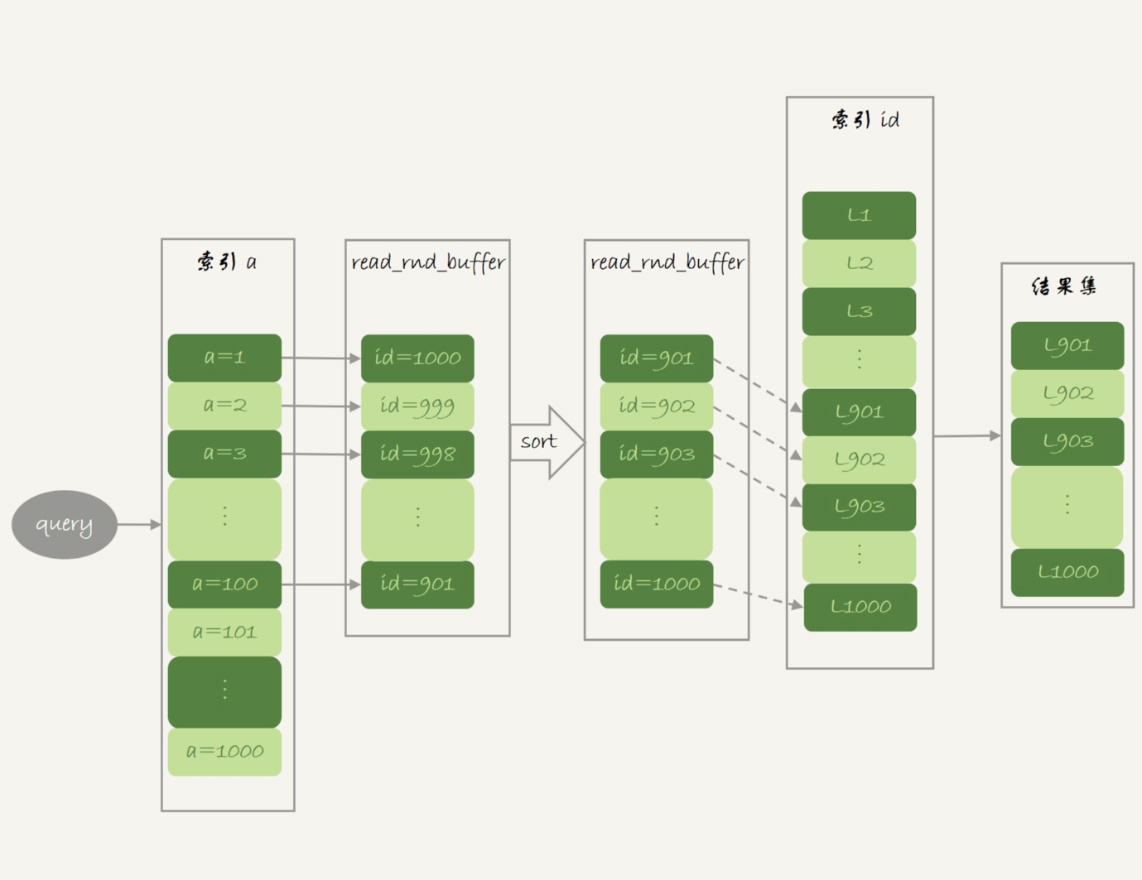
图2 MRR执行流程

==MRR能够提升性能的核心在于,这条查询语句在索引a上做的是一个范围查询(也就是说,这是一个多值查询),可以得到足够多的主键id。这样通过排序以后,再去主键索引查数据,才能体现出“顺序性”的优势。==
Batched Key Access
对Index Nested-Loop Join的一种优化,利用了join buffer缓存;
==MySQL已经默认做了这个优化,NLJ算法会自动转为BKA算法==
NLJ算法优化后的BKA算法的流程。
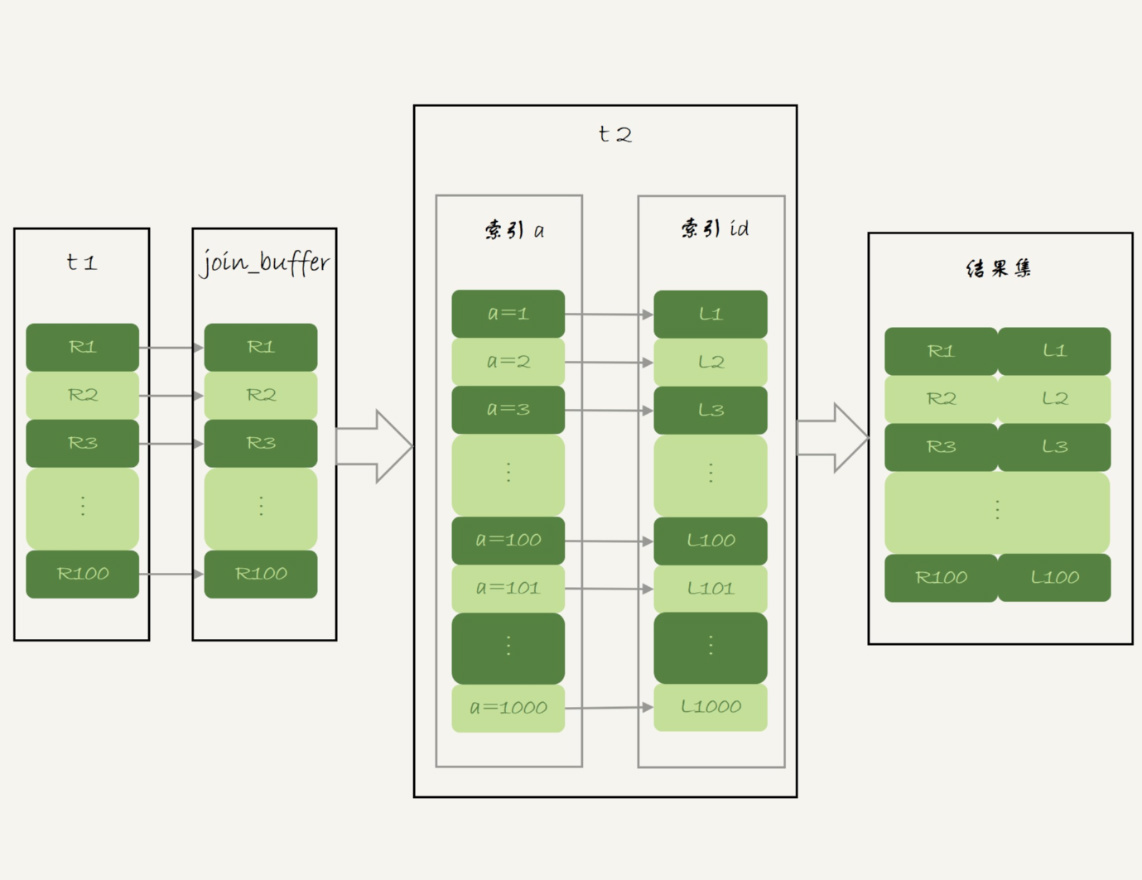
图5 Batched Key Acess流程
图中,我在join_buffer中放入的数据是P1到P100,表示的是只会取查询需要的字段。当然,如果join buffer放不下P1到P100的所有数据,就会把这100行数据分成多段执行上图的流程。
那么,这个BKA算法到底要怎么启用呢?
如果要使用BKA优化算法的话,你需要在执行SQL语句之前,先设置
1 | |
其中,前两个参数的作用是要启用MRR。这么做的原因是,BKA算法的优化要依赖于MRR。
优化
- 给被驱动表关联字段加上索引使得Block Nested-Loop Join转为Index Nested-Loop Join,经过join buffer的优化后转为Batched Key Access算法